Method
Stage 1: RL Pre-training with Soft Dynamics Constraints
In the RL pre-training stage, we allow robots to penetrate obstacles using an automatic curriculum that enforces soft dynamics constraints. This encourages robots to gradually learn to overcome these obstacles while minimizing penetrations.
Stage 2: RL Fine-tuning with Hard Dynamics Constraints
In the RL fine-tuning stage, we enforce all dynamics constraints and fine-tune the behaviors learned in the pre-training stage with realistic dynamics.
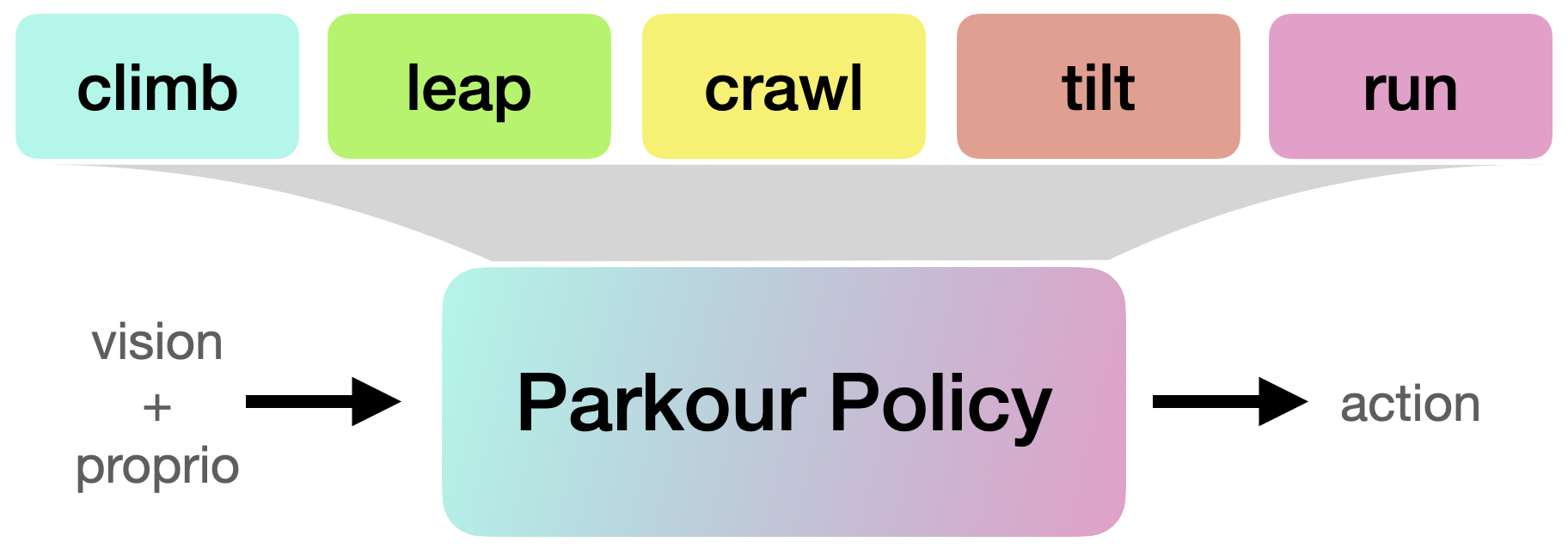
Stage 3: Learning a Vision-Based Parkour Policy via Distillation
After each individual parkour skill is learned, we use DAgger to distill them into a single vision-based parkour policy that can be deployed to a legged robot using only onboard perception and computation power.