
Robot Parkour Learning

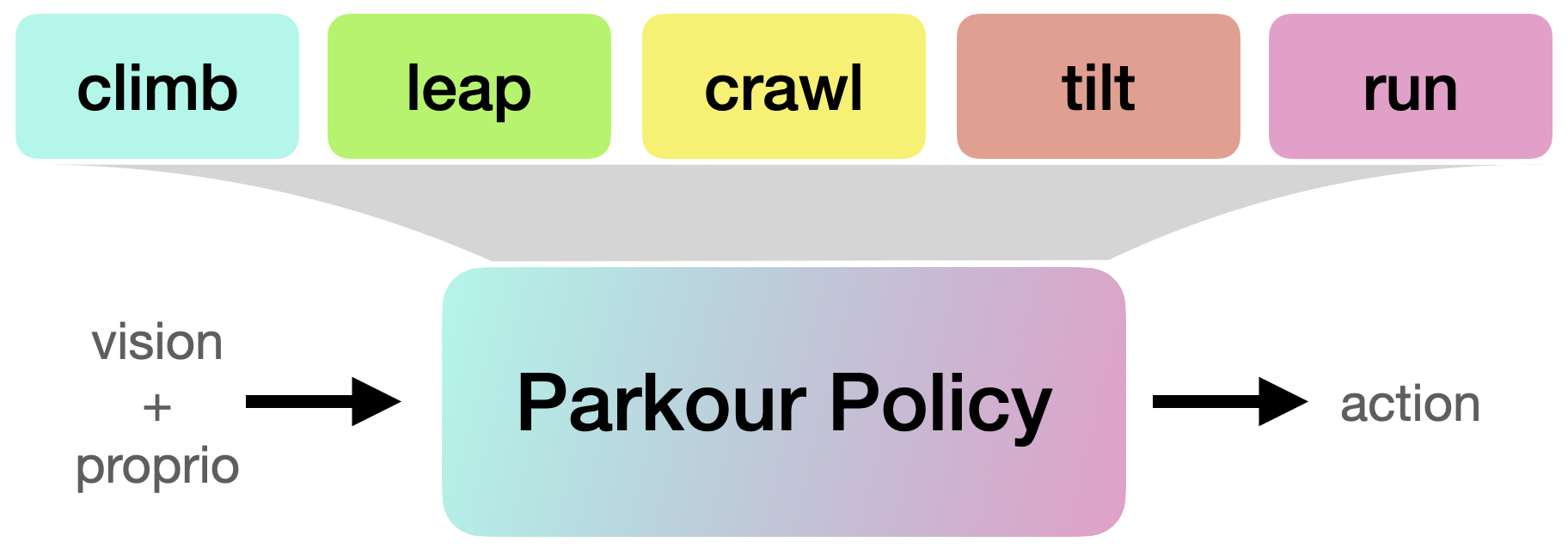
跑酷是对于足式机器人运动的一个巨大挑战,要求机器人在复杂环境中快速克服各种障碍。现有的方法要么通过预设地形进行没有自带外部感知能力的运动技能,或者采用基于视觉的方法针对每一个单独的技能收集参考的动物数据或者设计复杂的奖励函数。然而,自主跑酷要求机器人学习通用的、基于视觉的、多样化的技能,以感知和对各种情景做出反应。在这项工作中,我们提出了一个框架,通过使用简单的奖励而不需要任何参考运动数据,学习一个端到端的基于视觉的跑酷策略,可以自主执行各种跑酷技能。我们开发了一种通过direct collocation启发的强化学习方法,生成跑酷技能,包括爬过高障碍、跃过大间隙、爬行通过低矮障碍、穿过狭缝以及奔跑等。我们将这些技能蒸馏成一个基于视觉的跑酷策略,并且只采用机器狗自带的深度相机感知外部环境。我们演示了我们的系统可以在两种不同低成本的机器人上自主选择并执行适当的跑酷技能,以穿越具有挑战性的现实环境。
我们的跑酷策略允许机器人在初次尝试失败以后,持续重复尝试通过障碍物。通过强化学习策略,机器狗学会了将自己推离障碍物,从而保证自己有足够的准备距离再次尝试通过障碍物。
在强化学习预训练阶段,我们允许机器人穿过设定好的障碍物。并且,我们通过自动调整任务难度的方式来保证软动力学约束的合理性。这样的惩罚项鼓励机器人逐渐学会克服这些障碍物,并且避免穿透障碍物。
在强化学习微调阶段,我们强制执行所有的动力学约束,并且微调了第一阶段训练的策略。
在训练好每一个模拟环境中的跑酷策略后,我们采用DAgger的方式将他们蒸馏成一个单独的跑酷策略,并且部署在机器狗上。只采用机器狗自带的传感器以及机载算力。
在强化学习预训练阶段,我们允许机器人穿过设定好的障碍物。并且,我们通过自动调整任务难度的方式来保证软动力学约束的合理性。这样的惩罚项鼓励机器人逐渐学会克服这些障碍物,并且避免穿透障碍物。
在强化学习微调阶段,我们强制执行所有的动力学约束,并且微调了第一阶段训练的策略。
在训练好每一个模拟环境中的跑酷策略后,我们采用DAgger的方式将他们蒸馏成一个单独的跑酷策略,并且部署在机器狗上。只采用机器狗自带的传感器以及机载算力。